GNN Embeddings¶
BioNeuralNet leverages Graph Neural Networks (GNNs) to generate biologically meaningful, low-dimensional embeddings from multi-omics network data. These embeddings integrate complex biological interactions and structural information, facilitating accurate downstream analyses, such as phenotype prediction and biomarker discovery.
Core Features¶
Biologically Informed Embeddings: Models like GCN, GAT, GraphSAGE, and GIN produce embeddings informed by network connectivity and biologically relevant supervised signals (e.g., phenotype correlations).
Flexible, Modular Integration: Outputs structured as pandas DataFrames, seamlessly compatible with common bioinformatics workflows.
Comprehensive Workflow: Handles data from initial network construction through embedding generation to disease prediction in a unified, end-to-end pipeline.
Supported GNN Architectures¶
Graph Convolutional Network (GCN): GCN aggregates node features based on local neighborhood structure using spectral-based convolution:
where \(\widehat{A}\) adds self-loops to the adjacency matrix, ensuring that each node also considers its own features.
Graph Attention Network (GAT): GAT assigns learned attention scores to neighbors, enhancing model interpretability and accuracy:
with \(\alpha_{ij}^{(l)}\) representing the attention coefficient for node \(j\)’s contribution to node \(i\).
GraphSAGE: GraphSAGE performs inductive learning by aggregating neighboring node features to generalize effectively to unseen data:
where the mean aggregator provides a simple yet effective way to summarize local neighborhood information.
Graph Isomorphism Network (GIN): GIN leverages sum-aggregation and an MLP to discriminate subtle structural variations between graphs:
where \(\epsilon^{(l)}\) is either learnable or fixed.
Task-Driven Embeddings for Phenotype Prediction¶
BioNeuralNet generates embeddings optimized for disease prediction through supervised and semi-supervised training:
Phenotype-Guided Labels: Nodes labeled by correlation with clinical or phenotype data.
Supervised Training Objective: Minimizes MSE between predicted node correlations and actual phenotype correlations, ensuring biologically relevant embeddings.
Subject-Level Integration: Embeddings enhance patient-level datasets, significantly improving classification performance via DPMON (Disease Prediction using Multi-Omics Networks).
Embedding Generation Workflow¶
Embeddings produced by BioNeuralNet capture both topological and biological insights from multi-omics networks:
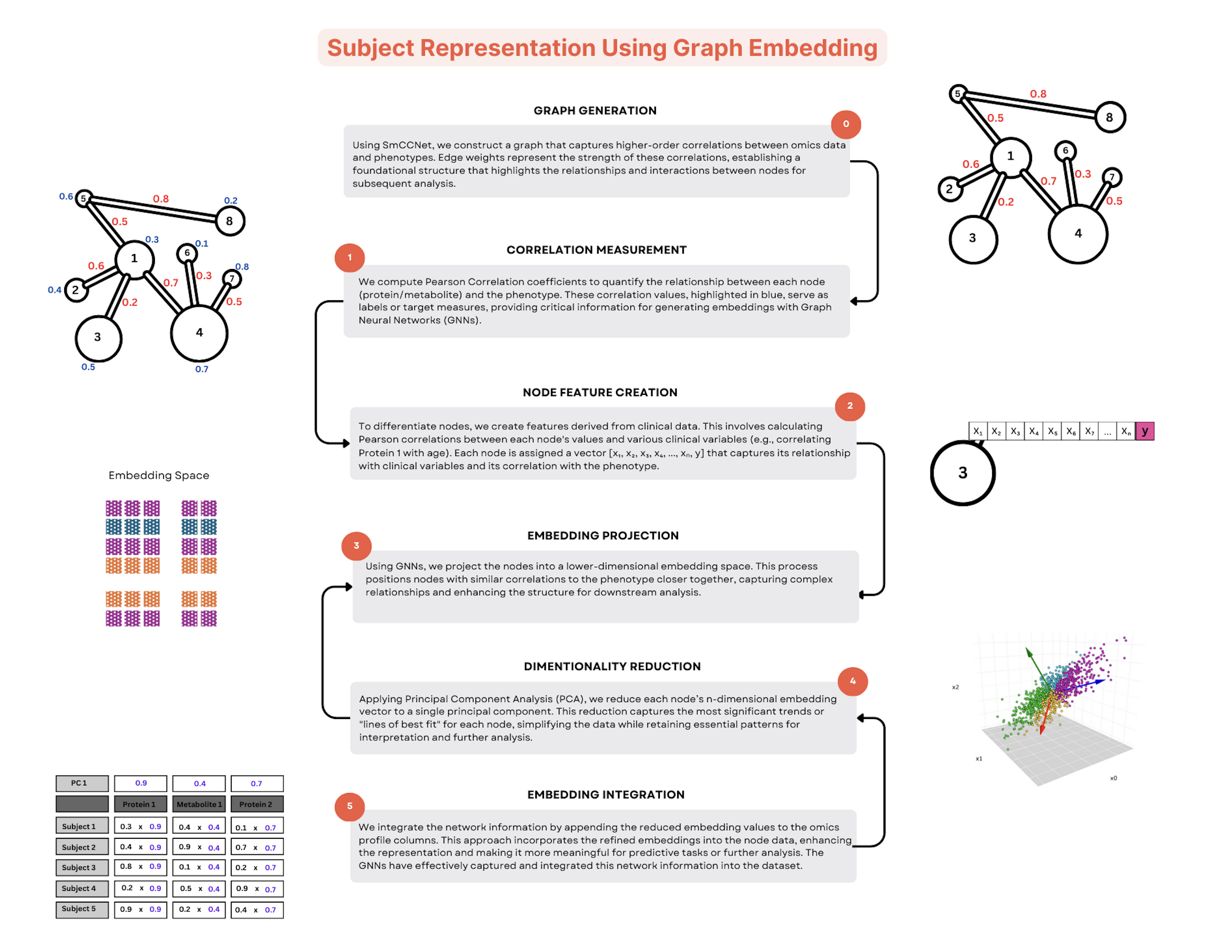
Workflow: Nodes labeled by phenotype correlation, embedded via GNNs, dimensionally reduced (PCA/Autoencoder), then integrated into subject-level data for enhanced predictive accuracy.¶
{kind=link}
Dimensionality Reduction¶
BioNeuralNet provides two main dimensionality reduction techniques post-GNN embedding:
PCA: Simple, linear, interpretable, suitable for datasets where linear assumptions hold.
Autoencoders: Nonlinear, flexible neural-network-based approach capturing complex biological patterns. Recommended with hyperparameter tuning (tune=True) for superior performance on highly dimensional or complex data.
How DPMON Utilizes GNN Embeddings¶
DPMON extends embedding applications to patient-level phenotype prediction:
Integrates node embeddings directly into patient-level features.
Uses a classification head (e.g., softmax with cross-entropy) trained to predict clinical outcomes.
Leverages both local molecular interaction information (node-level embeddings) and global omics data, yielding highly accurate phenotype predictions.
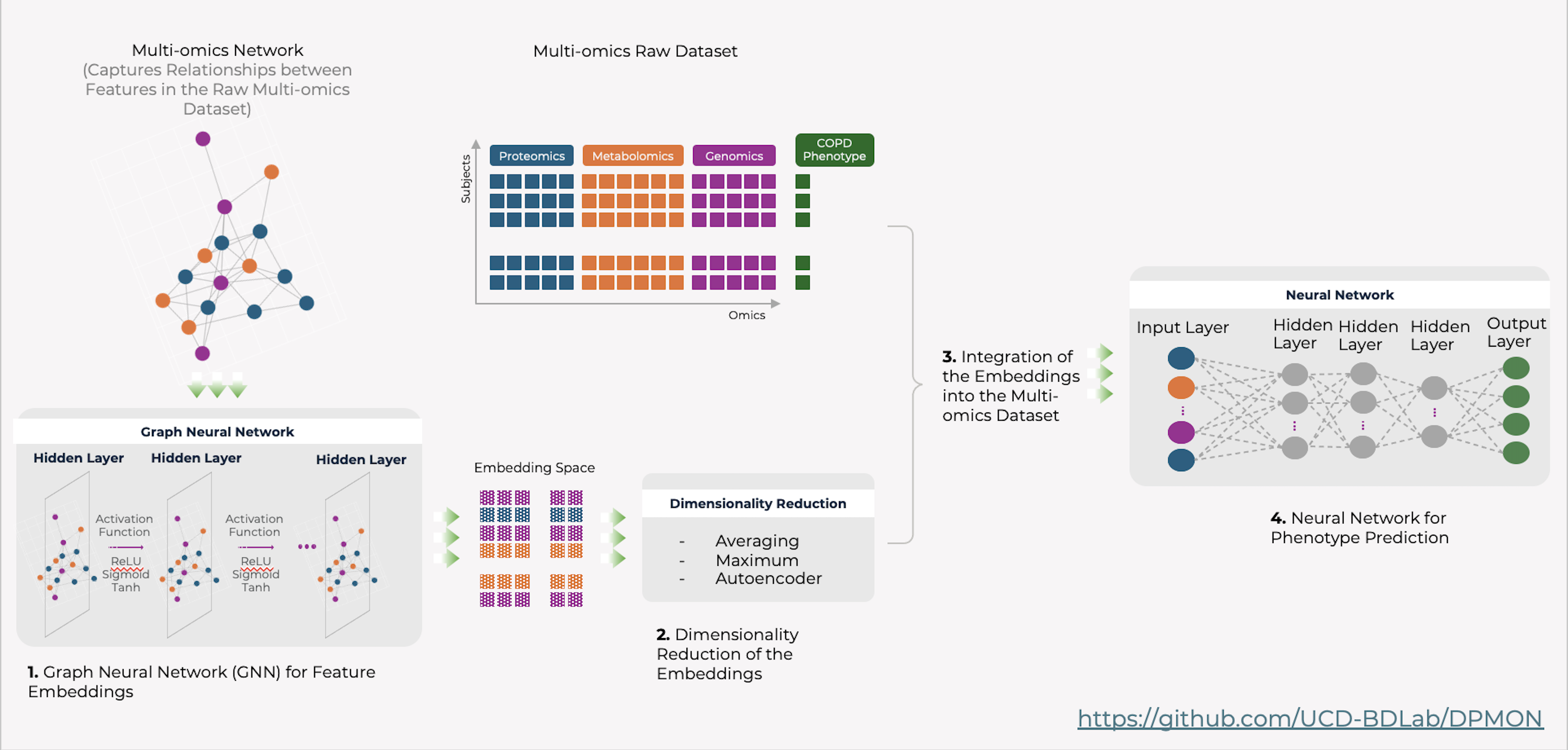
DPMON leverages GNN embeddings integrated with patient data for robust disease prediction.¶
View full-size image: Disease Prediction (DPMON)
{kind=link}
Return to BioNeuralNet: Graph Neural Networks for Multi-Omics Network Analysis